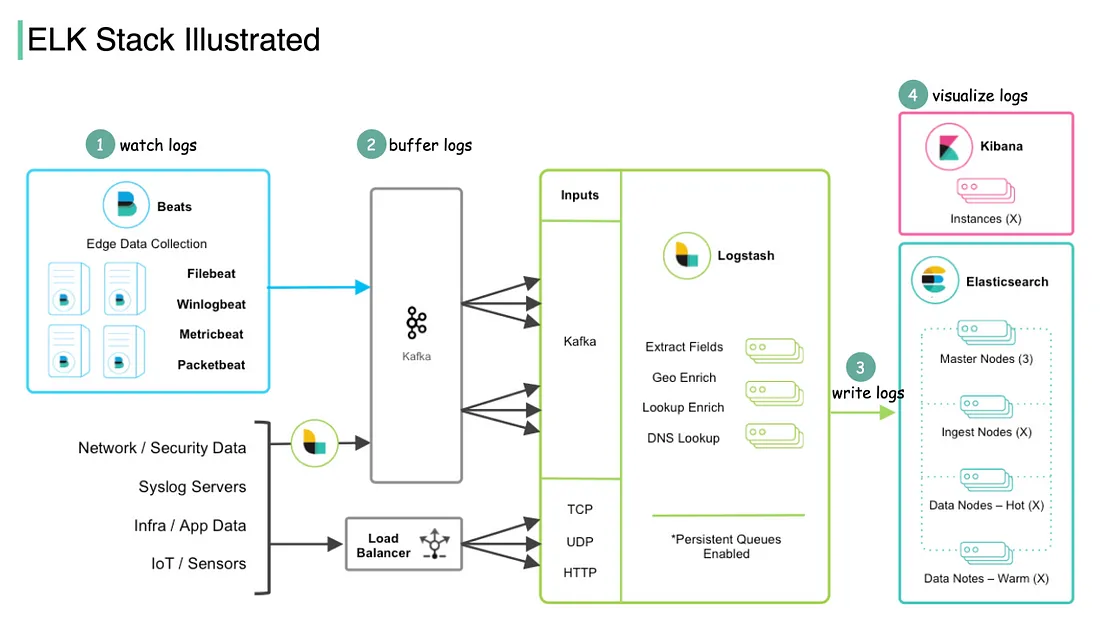
Sample ELK Stack Architecture
This architecture defines a powerful ELK Stack pipeline, incorporating
additional components such as Kafka for buffering and Beats for edge data collection. Together,
they enable reliable, scalable, and flexible real-time log monitoring and analytics. Each
component optimizes data flow—Beats for data collection, Kafka for buffering, Logstash for
processing, Elasticsearch for storage, and Kibana for visualization. This setup is ideal for
monitoring infrastructure, tracking security events, and detecting anomalies in real-time.
-
Watch Logs — Data Collection with Beats
Filebeat: Collects log files from various applications.
Winlogbeat: Gathers Windows Event Logs.
Metricbeat: Collects system and service metrics.
Packetbeat: Analyzes network packets to extract network traffic data.
Beats function as lightweight agents installed on edge servers or endpoints, responsible for
collecting logs, metrics, and network data for further processing.
-
Buffer Logs — Kafka
Once collected, the data from Beats is forwarded to Kafka, a
distributed streaming platform that acts as a buffer layer.
Kafka enables reliable data transfer and efficiently manages large data
volumes, preventing loss during high traffic or system disruptions. By buffering logs, it
ensures smooth handling of data ingestion spikes.
Load Balancer: Additional sources like network/security data, syslog
servers, and IoT sensors can send data directly through a load balancer, ensuring even
distribution of incoming data to Kafka.
-
Process and Write Logs — Logstash
Logstash retrieves data from Kafka and processes it by enriching,
filtering, and transforming it before forwarding it to storage. Key processing tasks include:
Extract Fields: Parsing logs to pull out relevant fields for analysis.
Geo Enrich: Enhancing data with geographical details based on IP
addresses, enabling location-based event tracking.
Lookup Enrichment & DNS Resolution: Enhancing data with additional
contextual information, such as hostname lookups.
Persistent Queues Enabled: Logstash utilizes persistent queues to
maintain data integrity, preventing loss during temporary outages.
-
Write Logs — Elasticsearch
Elasticsearch: After processing, data is stored in Elasticsearch,
where it is indexed and structured for fast search and analytics.
The Elasticsearch setup is shown as having multiple node types:
Master Nodes: Oversee the cluster by managing configuration,
monitoring cluster state, and coordinating operations.
Ingest Nodes:Handle data transformation if necessary.
Data Nodes:Responsible for storing and indexing data, categorized into
Hot and Warm nodes. Hot nodes store recent data for quick access, while Warm nodes
retain older data for cost-effective storage.
-
Visualize Logs — Kibana
Serving as the visualization layer and frontend, Kibana enables data
analysis through interactive dashboards and graphs. It connects to Elasticsearch, allowing users
to search, analyze, and visualize indexed data.
Kibana is essential for monitoring metrics, identifying trends, detecting
anomalies, and configuring alerts.